Openness to experience 独創的・好奇心が強い vs. 着実・警戒心が強い
Conscientiousness 手際が良い・まめな人 vs. 楽 天的・不注意
Extraversion 社交的・エネルギッシュ vs. 孤独を好む・控えめ
Agreeableness 人当たり良い・温情のある vs. 冷たい・不親切
Neuroticism 繊細・神経質 vs. 情緒安定・自信家
Kevin FordのUniversal Needs Map (欲求と社会的価値の関係)
ブランドの選択/ 商品の選択/ 職業の選択/・・・
Schwartzの価値概説
- Self-transcendence (自己超越)
- Conservation (保存)
- Self-enhancement(自己高揚)
- Open to change (変化に対する需要性)
テキストから性格を推定する仕組み
- 各手順を明確にし、ドキュメント化すること
- 業務システムの導入経験のある人材を準備すること
- SAP Business One の機能をよく理解した技術者を準備すること
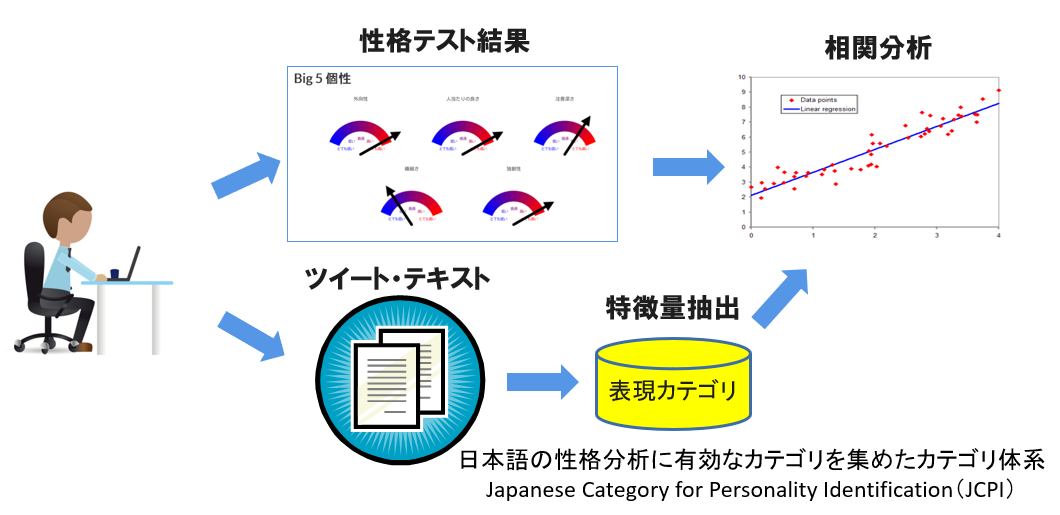
特徴量抽出方法
特定カテゴリの表現がどの程度含まれているかを分析
日本語の性格分析に有効なカテゴリを集めたカテゴリ体系を構築
-> Japanese Category for Personality Identification(JCPI)
下記構成要素からなる約90種類のカテゴリを設定
【構成要素】
助詞(〔格助詞〕〔係助詞〕など)
字種(〔漢字〕〔カタカナ〕など)といった日本語独特カテゴリ
〔読書〕〔遊び〕〔イベント〕(などの独自カテゴリ)
心理学の世界を中心に世界中で使われているLinguistic Inquiry and Word Count (LIWC) を参考にしたカテゴリ
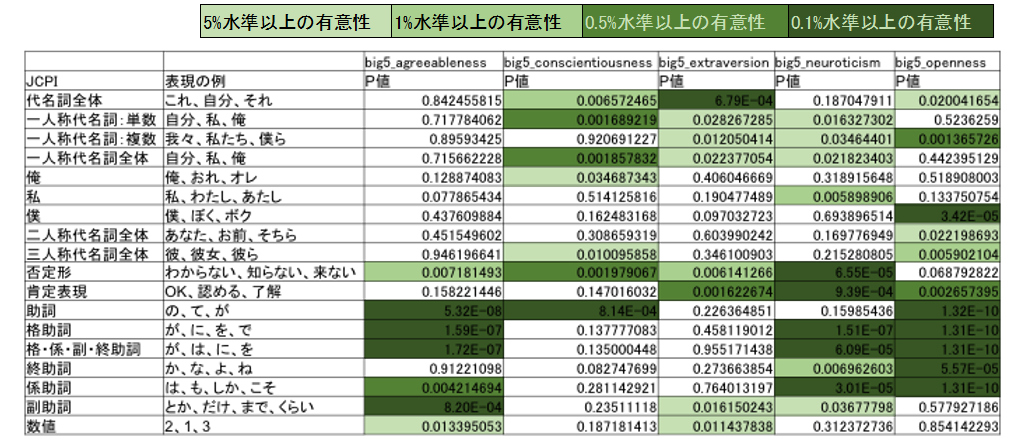
特徴量分析結果
サンプルデータ収集の結果、big5のそれぞれの要素と強い相関のある、特徴的な日本語表現が見つかっています。これらの特徴量を使って、機械学習モデルを構築しました。
各要素の性格値(0から1までの値を取る)の、予測値と実測値(性格分析結果)の比較を交差検定法(学習データ以外のデータで精度評価を行う)で行いました。
その結果、平均絶対誤差 (MAE) は約 0.1であることがわかっています。