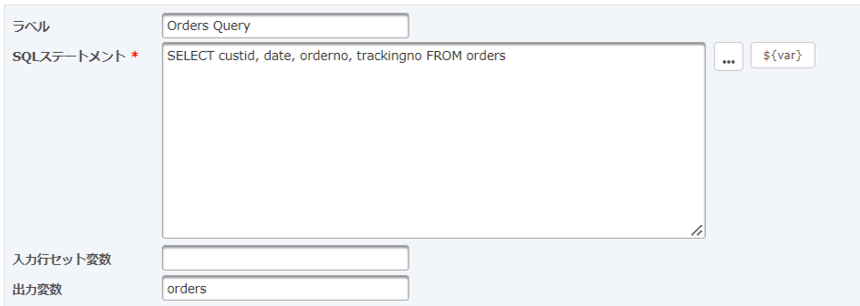
[追加する]ボタンをクリックし、クエリをSQLタスクに追加します。注文データベーステーブルに対して最初にクエリを作成します。
SQL StatementフィールドにSelectステートメントを入力します。または、SQLウィザードを使用して、Selectステートメントをすばやく構築できます。
SQLウィザードでは、スキーマ(ライブラリ)、テーブル(物理ファイル)、列(フィールド)、列見出し、 "where"句、および "order by"句を選択できます。
SELECTステートメントを作成するためのSQLウィザードにアクセスするには、SQLステートメントフィールドの右側にある参照アイコンをクリックします。