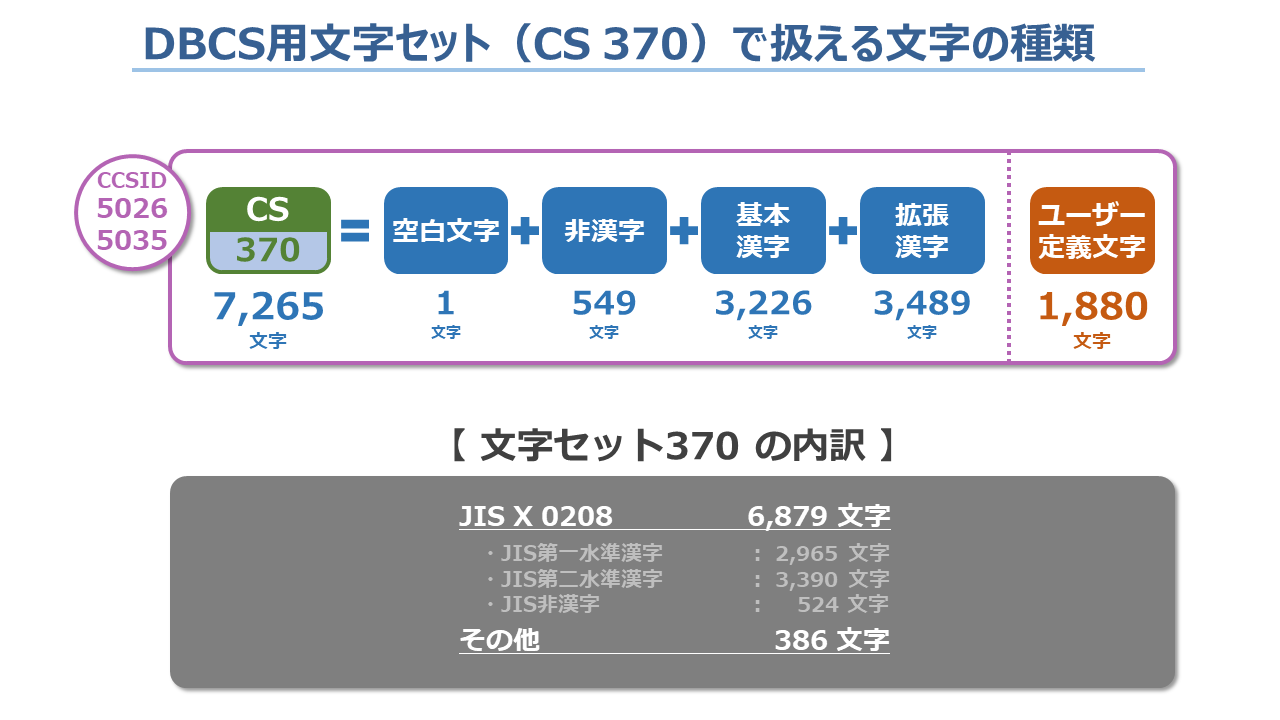
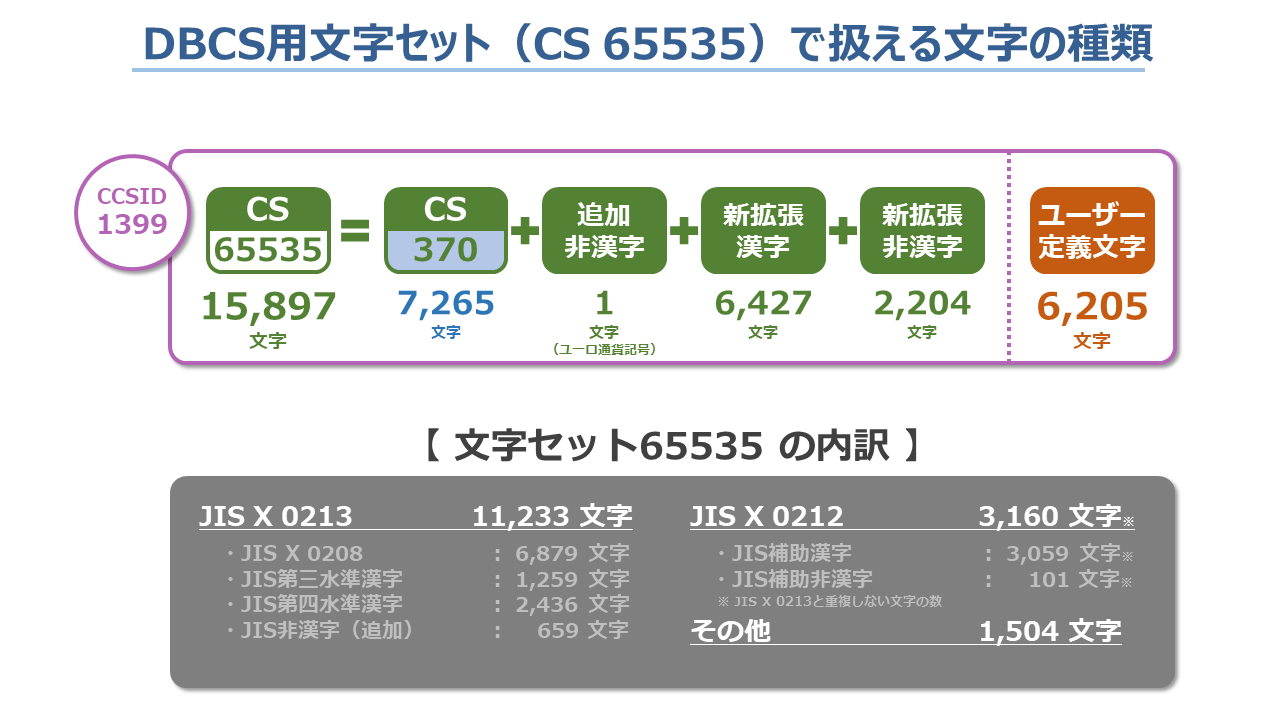
<DBCS用セットの違い>
次にDBCS用の内訳を眺めてみると、CCSID『5026』、『5035』、『1399』は全て同じコード・ページ『300』を使用していますが、CCSID『1399』だけは文字セットが『370』ではなく『65535』となっていて、他の2つのCCSIDとは異なります。
この文字セット『65535』は『Growing Character Set』(拡張する文字セット)と呼ばれるもので、扱える文字を随時拡張できる特殊な文字セットです。
SBCS用の文字セットも内包して、扱える文字の種類が格段に多いのが特徴です。
具体的には、文字セット『370』で扱える文字が7,265文字なのに対して、文字セット『65535』で扱える文字は現在15,897文字です。
また、使用できるユーザー定義文字(外字)も1,880文字から6,205文字に拡大しています。